今天为大家推荐的是一篇将 deep neural networks 和 logic rule 结合的文章,题目为《Harnessing Deep Neural Networks with Logic Rules》[1]。将这两者结合的出发点是很自然的,一来 deep neural networks 的不可解释性很令人困扰,二来可用于 training 的 labeled data 往往很少,training 也比较困难,希望能通过额外的 knowledge 来帮助 training。于是,logic rule 就成为了一种比较好的选择。它能很好地建模人类的认知思维和先验知识。
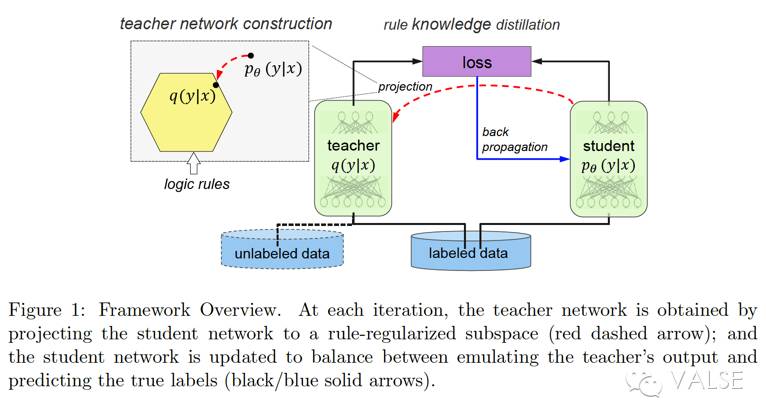
但是,这篇文章并不是直接将 logic rule 强行加入到某一个独立的 neural networks,而是将 logic rule 通过 posterior regularization 的方式建模到一个 teacher network 里,然后用 knowledge distillation 的方式将 teacher network 里的 knowledge “分享/传授”给 student network。这里需要注意到一组相关的概念:teacher-student network 和 parent-child network——两个都是 machine-to-machine learning paradigm。不同的是,teacher-student network 是让 student network 尽可能去借鉴吸取 teacher network 的“经验”,并不一定是完全 mimic,所以 student network 的 performance/outputs 可能和 teacher network 不同。然而,parent-child network 中,child 则被要求做到 mimic learning,学习 parent 的 outputs/parameters,甚至希望直接“继承”(inherit)parent 中已有的 knowledge。所以,在这篇文章中,他们是 teacher-student network。表现方式是,student network 被要求在 teacher network 的 outputs 和真实 label 之间做出 balance——借鉴 teacher network 的 knowledge,但不是无脑 copy。有了上面的概括,我们来继续分步说这些工作,即:(i)如何表达 logic;(ii)如何把 logic 加到 teacher network;(iii)teacher-student network 之间如何一起 train。拆开来看:
(i)他们是用 soft logic(而且是 first-order),特点就是在 [0,1] 之间连续取值。虽然这篇工作暂时还没有做,但是连续取值使得这个工作非常有扩展性,可以将各种 probabilistic 的东西加进去。soft logic 的形式如公式(1):
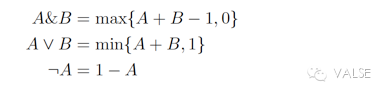
(ii)logic 加入 teacher network 的方式也是基本参考以前的 rule 加入 statistical model 的方法,即 posterior regularization(PR)。这个方法的好处是比较简单,其实就是一种 regularization,有 closed-form,不会增加额外的计算量(如 approximate algorithm)。那么,teacher network 的构建肯定是要尽可能的满足 rule——为此他们采用了 expection operator 的方式,即对于给定的具有某个 confidence 的 rule 和 labeled examples (X,Y),对于 teacher network 的 constraint 是:
有了这样的 constraint,teacher network construction 的第二个要求就是要找到尽可能 optimal 的 teacher network 分布 q,使得 q 在满足上面这个 rule constraint 的前提下尽可能地接近 student network 分布 p——这个“接近”就用两个分布之间常用的 KL divergence 来 measure,也就有了公式(3)和公式(4):
即在满足 rule 的这个 slack \epison 的 constraint 前提下,去最小化 p, q 的 KL divergence——这样就做到了把 p 映射到一个 logic rule constrained 的 subspace 中去了。而(4)就是这个(3)的 closed-form 解。
(iii)如何在 teacher-student network 之间“互通有无”,也就是具体如何 rule knowledge distillation。如上述,整个 training 的 guide 就是把 student network 的 p 投射到一个 rule-regularized 的 subspace 得到一个 q,然后利用 q 的 output 和真实 label 之间的 balance 结果去 update student network 自己的 p。这个 balance 的 objective function 就是公式(2):
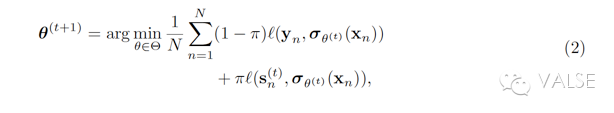
这里的 pi 就是一个线性参数,用来控制到底 balance 的倾向程度。注意(ii)中的公式(4)和(iii)中的的公式(2)连在一起看,一个是用 expectation 做 rule-regularization,一个是用 minimize loss 做 update——作者因此将他们这种方式比作 EM 算法版本的 posterior regularization。
到此为止,这篇论文的方法框架就介绍完了。可以看出,这种 knowledge distillation 的方式,是很 general 的,理论上可以适配于任何种类的 neural networks。在这篇文章中,作者分别在 CNN 和 RNN 这两个 typical networks 上做了检验,只不过实验中只涉及了 NLP tasks。也就是说,他们的 rule 都是 linguistic-related rule。在用 CNN 做 sentiment classification 时,用到的 rule 是 “but”引导的转折从句的情感应该主导整句话的情感。在用 RNN 做 NER 时,用到的 rule 也很类似,不做赘述了。
总结来看,这篇文章最大的贡献莫过于将 teacher-network 这种常常是 separate training 的方式,变成了 iterative 的类似 EM Algorithm 的一起 training。并且在实验中,作者也证实了这样 iterative 的一起 train 是很有帮助的。个人认为,现在的局限有几点:这篇文章暂时只检测了 rule with strong confidence;而且和原始 Bengio 那篇 Knowledge Distillation[2] 问题一样,虽然 claim knowledge distillation 的好处是可以将 unlabeled data 的 knowledge 用过来,但是实际在实验中的效果都是用一样的匹配的 labeled training data 会更好。其次,NLP task 的 rule 会比较好描述,其他领域的 knowledge(structured knowledge)是否也能融入到这个框架中呢?因为,image 中很多表达都是 pixel 这种 low-level 的,knowledge 的表达形式也会很不一样。这方面的工作还可以参考最新的 Stanford CS231n 课程 report[3]。诚然,这篇文章中的 knowledge distillation 只是我们常遇到的各类问题的其中一种。息息相关的还有 transfer learning,adaption,curriculum learning 等等。相信未来会有更多工作 focus on 在如何让 training 变得更加简单,可控,易于解释上。
[1] Zhiting Hu, Xuezhe Ma, Zhengzhong Liu, et al. Harnessing Deep Neural Networks with Logic Rule. 2016. arXiv preprint: 1603.06318.
[2] Geoffrey Hinton, Oriol Vinyals, Jeff Dean. Distilling the Knowledge in a Neural Network. 2015. arXiv preprint:1503.02531.
[3] Nathanael Romano and Robin Schucker. Distilling Knowledge to Specialist Networks for Clustered Classification. 2016. CS231n project report.




 发表于 2016-4-7 16:25:58
发表于 2016-4-7 16:25:58