机器学习日报 2015-07-19
@好东西传送门 出品, 过往目录 见http://ml.memect.com
订阅:给 hao@memect.com 发封空信, 标题: 订阅机器学习日报 或点击
本期话题有: 全部27 算法11 资源8 自然语言处理7 深度学习5 应用4 会议活动3 经验总结2 进化计算1 视觉1
用日报搜索找到以前分享的内容: http://ml.memect.com/search/ 今日焦点 (5)
 poetniu 网页版 2015-07-19 16:06 poetniu 网页版 2015-07-19 16:06
深度学习 算法 集成学习 神经网络
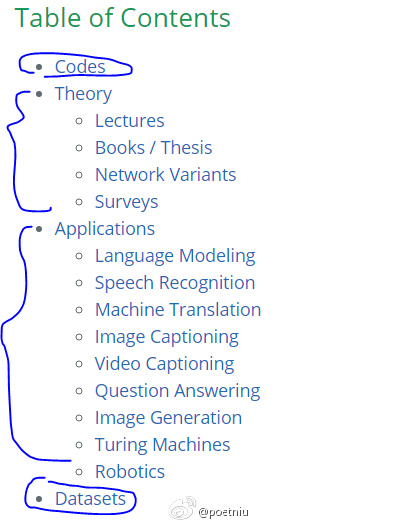
这个系列挺好 Awesome Recurrent Neural Networks http://t.cn/RLI8bZ1 Awesome Random Forest http://t.cn/RLtzya3 Awesome Deep Vision http://t.cn/RLvTzjR
 iB37 网页版 2015-07-19 22:43 iB37 网页版 2015-07-19 22:43
算法 应用 资源 PDF SVM 教育网站 信息检索
KDD15#Test of Time# 1)SVM-light作者T.Joachims[Optimizing Search Engines using Clickthrough Data,KDD02] http://t.cn/RhG9G4d 2)B.Liu老师<用户评论的挖掘与摘要,KDD04>http://t.cn/RLMhyNL 3)<机器学习那些事儿>作者P.Domingos [Mining High-Speed Data Streams,KDD00] http://t.cn/RLMhyNy

 爱可可-爱生活 网页版 2015-07-19 21:42 爱可可-爱生活 网页版 2015-07-19 21:42
深度学习 资源 Keith Adams 视频
【视频:Facebook加速深度学习】《XLDB2015: Accelerating Deep Learning at Facebook》by Keith Adams http://t.cn/RLIsA5F 云:http://t.cn/RLIsA5k
 星空下的巫师 网页版 2015-07-19 16:13 星空下的巫师 网页版 2015-07-19 16:13
进化计算 算法 Python 神经网络
Genetic Algorithm in 15 lines of Python code:A simple yet effective genetic algorithm implementation used to train a neural network in 15 lines of code. #15行Python代码使用GA算法训练网络# http://t.cn/RLI8KZc

 成华区学无涯书社 网页版 2015-07-19 09:33 成华区学无涯书社 网页版 2015-07-19 09:33
视觉 算法 资源 书籍
每日新书:《稀疏与冗余表示–理论及其在信号与图像处理中的应用》全面介绍了稀疏和冗余表示模型和它在信号和图像处理中的应用。本书系统地、有条理地展示了该模型的理论基础、求解算法的数值分析和由此受益的信号和图像处理应用。书中对分析目标提供了非正式的描述,并构造了给出证明的方法。

最新动态
2015-07-19 (21)
 agentzh 网页版 2015-07-19 21:31 agentzh 网页版 2015-07-19 21:31
算法 应用 预测 正则表达式
再接再厉,我又给 sregex DFA 引擎原型添加了个简单的优化,即对于较多分支的情况,在输出的 C 目标代码中使用 switch/case 语句。clang 和 gcc 会把 case 多于或等于 5 的 switch 语句编译为所谓的“jump table”,从而实现 O(1) 的时间开销,同时避免了 branch mis-prediction. 该优化的效果很显著。

agentzh 网页版 转发于2015-07-19 21:35
如果没有此优化,则对于下面两个简单的分支选择的正则表达式,我的新引擎的效率反而显著低于 PCRE JIT;而一旦开启该优化,则立即反超 PCRE JIT. 我知道 PCRE JIT 吐的机器码充分考虑了 code layout 对 branch 的影响。所以我们这里也不能大意。有趣的是,clang 在这里生成的代码明显比 gcc 效率高。
agentzh 网页版 转发于2015-07-19 21:44
Google 的 RE2 引擎在这一组性能测试中又几乎垫底了。这是因为所有这些测试用例都使用的是 submatch capture 模式,而在此模式下 RE2 几乎总是退到 NFA 仿真算法,虽然是 O(n) 的时间复杂度,但却是非常慢的 O(n),呵呵。另外,RE2 使用平衡树来匹配字符区间,自然没法和 jump table 比了。
爱可可-爱生活 网页版 2015-07-19 21:13
深度学习 论文
【论文:量子衍生DBM高效训练方法】《Quantum Inspired Training for Boltzmann Machines》N Wiebe, A Kapoor, C Granade, KM Svore [Microsoft] (2015) http://t.cn/RLIkH6l参阅该作者另一篇《Quantum Deep Learning》(2014) http://t.cn/RzQGGl2

爱可可-爱生活 网页版 2015-07-19 21:05
算法 回归 决策树
【Quora:logistic回归 vs. 决策树】《What are the advantages of logistic regression over decision trees?》http://t.cn/RLIkt0Q
 ML_Yuens 网页版 2015-07-19 20:14 ML_Yuens 网页版 2015-07-19 20:14
经验总结 深度学习 算法 博客 神经网络
Convolutional Neural Networks (卷积神经网络) – the_Gaven – 博客园 http://t.cn/RLIgpxi
agentzh 网页版 2015-07-19 17:04
正则表达式
刚刚给我的 sregex DFA 正则引擎的原型实现又添加了个有趣的优化,即针对适用于 memchr() 单字节搜索的 DFA 状态,施用 memchr(). 由于 DFA 的确定性,不仅正则的起始状态可能适用该优化,中间的某些状态也可能适用。比如下图是正则 /d.*d/ 对应的 DFA,其中[1]、[3]、[6]号 DFA 状态都满足优化条件。

agentzh 网页版 转发于2015-07-19 17:11
这种优化对于某些特殊输入效果显著。比如用刚才那个正则 /d.*d/ 匹配一个首尾是字母 d 而中间是 10M 个字母 a、b、c 的随机组合,我的新引擎在开启 memchr 优化前后的匹配时间分别是 4.71ms 和 0.95ms. 提升达到近 5x. 不过有些奇怪的是,RE2 号称也有此优化,但在这个例子中巨慢无比,用时达 1.4 秒多
彤言彤趣 网页版 转发于2015-07-19 18:15
种优化对于某些特殊输入效果显著。比如用刚才那个正则 /d.*d/ 匹配一个首尾是字母 d 而中间是 10M 个字母 a、b、c 的随机组合,我的新引擎在开启 memchr 优化前后的匹配时间分别是 4.71ms 和 0.95ms. 提升达到近 5x. 不过有些奇怪的是,RE2 号称也有此优化,但在这个例子中巨慢无比,用时达 1.4 秒多
agentzh 网页版 转发于2015-07-19 21:21 回复 @HalfAMonk “这例子也太极端了!”
极端的例子最能检验算法的效果和实现的正确性。另外从安全的角度看(比如将之用于 Web 防火墙),最有趣的往往是最坏情况。
 licstar 网页版 2015-07-19 16:05 licstar 网页版 2015-07-19 16:05
自然语言处理
7月24日到7月30日 NLP盛宴汇总贴 http://t.cn/RLIQ3GD

iB37 网页版 2015-07-19 13:57
会议活动 应用 AAAI ICML IJCAI 广告系统 会议 推荐系统
对于有较多回头客的个性化广告推荐PAR,优化点击率CTR也许不是一个好的度量。Personalized Ad Recommendation Systems for Life-Time Value Optimization with Guarantees [Theocharous,IJCAI15] 通过HCOPE [Thomas,AAAI15,ICML15] 和强化学习,优化客户的终身价值LTV http://t.cn/RLIWtks

 王威廉 网页版 2015-07-19 12:48 王威廉 网页版 2015-07-19 12:48
算法 资源 Python 课程 神经网络
挺有意思的Python教程:用11行Python写一个简单的神经网络。http://t.cn/RLINMXx
 好东西传送门 网页版 2015-07-19 11:45 好东西传送门 网页版 2015-07-19 11:45
会议活动 自然语言处理 活动 机器翻译
NLP日报 2015-07-18 http://t.cn/RLIKZLK 1) 论文: 神经机器翻译中稀有词问题的缓解 2) 论文: 提升词重要性估计用于新闻多文档摘要 3) Slav Petrov学术报告 完整版11条 http://t.cn/RLIKZL9

好东西传送门 网页版 2015-07-19 11:43
会议活动 自然语言处理 ICML Leon Bottou 会议 机器翻译 简报
机器学习日报 2015-07-18 http://t.cn/RLIokQn 1) Leon Bottou在ICML的主题演讲:机器学习的两大挑战 2) 关联聚类——从理论到实践 3) 组合用户特征和图片特征用于图片hashtag预测 4) 神经机器翻译中稀有词问题的缓解 5) 提升词重要性估计用于新闻多文档摘要 完整版25条http://t.cn/RLIokQm

王威廉 网页版 2015-07-19 11:29
资源 Peter Norvig Stuart Russell 书籍
Stuart Russell和Peter Norvig关于人工智能和图灵测试有意思的论述:设计复杂的科技不必模仿生物形态,飞机也不必像鸟一般飞翔。图灵测试就好比去骗鸟,让鸟去相信飞机是他们中的一员,从而证明飞机真的是飞行机器。《纽约时报》:http://t.cn/RwCgeG3
 梁斌penny 网页版 2015-07-19 10:57 梁斌penny 网页版 2015-07-19 10:57
自然语言处理
在实验室把一个个实验按照实验步骤又重做了一遍,rm命令之前,向他们道别了。再说一个实验结论吧:当小数据集的时候,如果有一部分监督学习语料是刻意乱标的(比如10%),模型是抵抗不住这种干扰的。但如果是大数据集,10%的乱标,根本不影响结果,还是要在大规模语料上学习才行。
梁斌penny 网页版 2015-07-19 10:44
深度学习
我发现深度学习一个实验现象,如果稀疏约束(比如lazzo)加太狠了,且隐节点少了,可能无法训练出区分度很好的结果,如果加大隐节点数量就解决了。我感觉,隐节点越多越容易过拟合,稀疏约束越强越能解除过拟合。两个作用力互相消涨,但总体上讲,猛一点的稀疏约束+多一点的隐节点数量,效果更好
 JoeChristmas 网页版 2015-07-19 07:00 JoeChristmas 网页版 2015-07-19 07:00
资源 Guido Imbens Susan Athey 幻灯片
听了susan athey和guido imbens关于machine learning的讲座,脚着这个领域太好玩了。转发一下slides: http://t.cn/RLItWzr
爱可可-爱生活 网页版 2015-07-19 05:56
算法 Forest Kernel 代码 集成学习 论文
【论文+代码:Random Forest Kernel & Fast Cluster Kernel】《The Random Forest Kernel and creating other kernels for big data from random partitions》A Davies, Z Ghahramani [Cambridge] (CoRR 2014) http://t.cn/RLI54wg GitHub:http://t.cn/RLI54wd

爱可可-爱生活 网页版 2015-07-19 05:43
资源 PDF Yanchang Zhao 书籍
【免费书:R与数据挖掘最佳实践/经典案例】《R and Data Mining: Examples and Case Studies》by Yanchang Zhao (2013) http://t.cn/RLIqFy9 官网:http://t.cn/RLIqFyN云:http://t.cn/RLIqFyC

爱可可-爱生活 网页版 2015-07-19 05:26
算法 应用 自然语言处理 KNN Python 代码 聚类 推荐系统
【Python机器学习实例:用KNN做Reddit子话题推荐】《Recommending Subreddits by Computing User Similarity: An Introduction to Machine Learning in Python》http://t.cn/RLIqT2f GitHub:http://t.cn/RLIqT2I
 Copper_PKU 网页版 2015-07-19 02:50 Copper_PKU 网页版 2015-07-19 02:50
自然语言处理 教育网站
http://t.cn/SylyGf conference for NLP/CL, full-list
Copper_PKU 网页版 2015-07-19 01:53
资源 自然语言处理 教育网站 课程
http://t.cn/RLIUDo4 Machine Translation Tutorial
 winsty 网页版 2015-07-19 00:49 winsty 网页版 2015-07-19 00:49
这个年头还在争论arxiv该不该被cite这样的问题真是无趣。现在该讨论的是arxiv应该怎样以一个更好的形式呈现,而不是心理上莫名的反感。历史上每次出现提高生产效率的工具一定是会有各种旧势力的阻碍。的确arxiv的出现让节奏大大加快,很多人累感不爱,但一个合格的PhD应该直面挑战,而不是掩耳盗铃。
winsty 网页版 转发于2015-07-19 00:52
至于对某人的个人评价,我最讨厌的事情是 1) 对不了解的事情指手画脚 2) 对没把握的事情用十分把握说出来 3) 把自己个人的偏好绑架于别人。某人恰恰三条都占齐了。不得不承认我还是很喜闻乐见的。(第一次在知乎有这么多人实名反对有感,哈哈)
孔明_CASIA 网页版 转发于2015-07-19 09:06 回复 @鲁东东胖 “完全赞同!因为有了arXiv 和微博…”
没有了同行评审,质量如何保证?这是关键。
鲁东东胖 网页版 转发于2015-07-19 09:12 回复 @孔明_CASIA “没有了同行评审,质量如何保证?…”
瑕不掩瑜,而且的确还有很大可改进的空间,换句话说,很多会议评审什么的质量保证也是呵呵…
winsty 网页版 转发于2015-07-19 09:43 回复 @喵星人BX “以现在一些顶级会议的个别评审意…”
严重同意,我在学校组织了arxiv paper reading,我们拭目以待这些paper最后能中多少
agentzh 网页版 2015-07-19 00:31
正则表达式
今天终于让我的 sregex DFA 引擎的 Perl 原型直接吐完全独立的 C 代码了。它生成的 C 程序通过 gcc 优化编译生成二进制程序后,可以独立地执行正则匹配任务。我拿正则表达式 /(a|b)aa(aa|bb)cc(a|b)/ 对一个 5.1MB 的大字符串进行匹配,同时与 PCRE 和 RE2 这些正则引擎进行性能比较,还是非常乐观的。

agentzh 网页版 转发于2015-07-19 00:45
当然,最终 sregex 的 DFA 引擎将不会依赖于 gcc 这样的外部编译器工具链,而是内建各种传统优化编证器里的优化算法,然后直接在内存里生成机器代码(类似 JIT 编译器)。所以这里借用 gcc 进行优化,结果可能会比最终的效果略好一些。值得一提的是,我们还尚未进行 DFA 最小化之类的高层面优化呢。
agentzh 网页版 转发于2015-07-19 09:51
这个吐 C 代码的 re.pl 原型实现同时还引入了 DFA 边的优化排序,同时对于 DFA 边构成字符全集的情形,最后一条 DFA 边在目标代码中不再做条件测试。这些优化的效果很明显。目前 re.pl 的代码量增加到 1487 行(除去空行和注释)。gcc/clang 生成的警告也能指示出我的 DFA 中一些冗余和不一致的地方。
| 






 发表于 2015-7-20 08:47:55
发表于 2015-7-20 08:47:55