|
|
|
从机器学习的视角来看偏激 2015-05-20 郭瑞东 [url=]混沌巡洋舰[/url] 混沌巡洋舰 混沌巡洋舰 [img][/img] 微信号 chaoscruiser 功能介绍 一门新兴学科,正悄悄重塑我们对世界的理解。经济,政治,物理,心理,看似不相关,却被一个叫复杂科学的学科深层相连。我们将带你从它的视角,看世界的全景。

鲁迅曾经说过:“当我沉默的时候,我觉得充实;我将开口,同时感到空虚",当我们逐渐长大,谈论起世事,大多多了一分谨慎,我们需要清楚的定义自己所说的是什么,不然那些夸夸其谈又有什么意思了。比如今天我想说偏激,可偏激是什么了。韩寒年轻时被指着为偏激,这些年又成了大众名人,公共知识分子。我们也许能给偏激下定义,也许能举出许多偏激的例子,可这些都无法准确的说明什么是偏激。于是智者便如苏格拉底般承认自己的无知,只留下一知半解的人指责着别人的偏激。于是就有了”与其做一头快乐的猪,不如做一个痛苦的思想者。“的名言。做一个思考着之所以痛苦,就在于其思考没有一个明晰的基础。
但科技的进步也会为思考着带来启迪。当我们可以创造一个模型,来模拟人脑的时候,我们也许就能更建设性的谈论偏激。在我们构造的模型下,我们可以客观的分析,可以做实验。比如我最近看的神经网络的课程,就可以作为一个人脑的一个模型。人的大脑是在不断的学习,学习后进行分类或者预测,而神经网络也是从training set中学习,从而进行对test set的行为预测。而神经网络(或者一般所有的机器学习中)都会有overfitting(过拟合)的问题,而在我看来,与overfitingt对应的,在人类社会中出现的问题就是偏激,或者可以称之为短视。
机器学习要解决的一类问题是分类问题,即将猫的照片和狗的照片分开。其中训练集是给计算机一万张猫的照片,一万张狗的照片,然后让计算机算法去处理这个训练集,之后拿十张猫的照片,十张狗的照片,这就是测试集。所谓overfitting,即所训练的网络在训练集上表现良好(有良好的解释能力),但遇到新的数据,则差之千里。为了得到一致假设而使假设变得过度复杂称为过拟合。想像某种学习算法产生了一个过拟合的分类器,这个分类器能够百分之百的正确分类样本数据(即再拿样本中的文档来给它,它绝对不会分错),但也就为了能够对样本完全正确的分类,使得它的构造如此精细复杂,规则如此严格,以至于任何与样本数据稍有不同的文档它全都认为不属于这个类别。
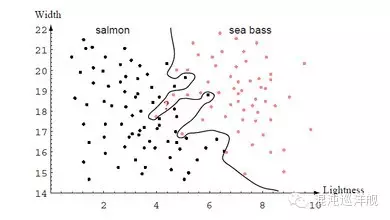
本图中的曲线有过拟合的可能,其对训练集的依赖过强,而对新的数据的表现可能会较差。
人一生性格的发展其实也是一个不断training的过程。最开始建立了一个model,随着人年龄的增长,阅历被当作training set来training这个model。当老处在一个相对固定的环境时,慢慢的overfitting问题就会出现,总在trainning set上获得较高的performance,即在这个环境下自己的性格model已经被training的可以游刃有余的处理任何人际关系和事情。然而当遇到新的环境时,突然自己的的这套model失效了。自然人比较奇怪的一点是往往在遇到这种情况时,没有勇气来对model进行修改或者将新的事件加到training set中optimize这个model。或许这就是artificial intelligent与nature intelligent的区别吧。抑或可以用来解释为什么人们总“乐于”帮助别人解决问题却没有勇气来解决自身问题
对于在人类社会中,我想到最典型的例子就是中国的文官制度,把这套制度看成是一个神经网络,任务时根据保障社会的和谐运作,这套制度在几千年里运行的总体上都不差,但这段时间,国内的情况变化不大,相当与在一个相当稳定的训练集上error很小,网络不断试图减小error,就好比历朝历代对文管制的小修小补。但到了鸦片战争,从训练集一下转到了一个全新的test set,中国这个overfitting的系统就出了大错误了。
Overfitting 的根源在于把 sampling(取样)中的regularity当成了实际数据中的regularity,而偏激的人则往往是由一件事(取样)而得出一个过分generalized的结论。同样,在神经网络中,之所以会出现overfitting的网络,也都是hidden unit过多,hidden layer过多的网络,即功能过强的网络,同样的类比,偏激的人大多聪明,一个人若不聪明,也不会叶落知秋的。Overfitting的另一个来源是hidden layer间的复杂的合作,导致一部分hidden unit去补偿另外一部分hidden unit的错误,而这种补偿带来的即这个神经网络只适用于这一部分数据,而同样的道理,人心的的偏激也可能是源于你想的太多,想法之间相互关联,让本应独立运作的模块有了虚拟的相关性。
而克服overfitting,按照我了解的,有很多方法,这里不能一一例举,只是就想到的约略说一些。
第一种是提供更多的训练数据,对应到人上面,则是见多识广可以使人考虑问题周全。这是最简单的方法,对于分类问题,我们即要给训练集即提供标签为正确的数据,也提供标签为错误的数据,就像孩子在成长的时候既要有成功也要有失败,既要见识到人性的恶与残忍,也要了解到人性的善于慈悲,只有这样,方能健康成长。
第二种克服overfit的方法是限制网络的能力,具体来讲,有early stopping, weight decay, noise等。Early stopping就是在网络的weight,对应到人这里,就是信念的强度,达到一定阀值时就阻止网络继续学习,我看到这里,便想起了中庸之道,不偏不倚,不要对某一观点过于执着,不就是不要讲某个hidden unit的weight设的过高吗,(可以把hidden unit代表的feature当做一个人的一个想法,weight对应人的执着程度)early stopping将网络的初始weight都设的很小,就像小孩子一开始对什么都没有什么观点。一个从小经受中庸之道熏陶的人应该是处变不惊的,就像一个带有early stop机制的网络具有更好的generalization。Weight decay(or weight constrain)的intuition是对于过大的weight,给予惩罚,对应到人类社会,则是批评某些人偏激,或者自觉自己的点子荒谬无稽。既然weight decay在神经网络中是一种可行的方法,那当我们被批评为偏激的时候,也不应觉得这是无稽之谈,是扼杀创造力,也许这些批评让你现在觉得不舒服,就像weight decay会降低网络在training set上的效果,但使用了weight decay,会使提高网络的generalization,这好比忠言逆耳利于行。限制网络能力的另一方法是在训练集的数据中加入IID的高斯噪音,这样同样增加了网络面对无噪音训练集时出错的频率,但提高了generalization,这条在人类社会中也有对于,一个从来没有听过谎言的孩子无法分辨真假,一个社会要是许久都没有谣言,那么一条谣言则会造成灾难性的影响,当家长过度的保护孩子,使他们无法接触到noise,那么他们今后面对鱼龙混杂信息的适应力也不会太好。老子云:“曲则全,枉则直”,岂是虚言。我们有无偏的数据,但为了网络的generalization,我们需要在数据中加入噪音,但这些噪音必须是独立的。
第三种克服overfitting的方法是综合多个网络(或者不同机器学习模型)的输出,这种方法对应的是兼听则明偏信则暗。除了使用多个不同的网络,也可以使用同一个规模较小的网络结构,但给予多个网络不同的训练集,使其specialize,同时加入一个负责control的网络,针对每一个网络给出的输出,给予一个对应的weight,面对预测集时则时给出网络的加权平均值,这个对于是现代社会的专业化,组长要组员专注于一个领域,同时对于不同的需求(即预测集的数据),通过给予组员意见不同的权重,来给出整个小组的答案。
第四种克服overfitting的方式在于将所要考虑的数据投射到一个高维度的空间上(这也是SVM的扩展性好,不容易出现过拟合的原因)。而这的关键是你首先要知道观察分析事物还有其他的维度,而这需要你视野开阔,不断吸收总结新的知识,之后通过将遇到的事在不同文化背景,不同情绪,不同时间轴上进行重新的framing,(类似于核函数),我们才能不以自己的价值观去评判别人。
最后要谈的克服overfitting的方法是boosting,一言以蔽之,也就是,三个臭皮匠赛过诸葛亮。该算法最初由Schapire提出。该算法先从样本整体集合D中,不放回的随机抽样n1 < n 个样本,得到集合 D1,训练弱分类器C1;再从样本整体集合D中,抽取 n2 < n 个样本,其中合并进一半被 C1 分类错误的样本。得到样本集合 D2,训练弱分类器C2,再抽取D样本集合中,C1 和 C2 分类不一致样本,组成D3,训练弱分类器C3,最后用三个分类器做投票,得到最后分类结果。这个算法本身就说明了问题,我们每个人看问题时也许不够全面,就像每一个弱分类器,但只要我们选择样本的角度是独立的,那么我们的偏见会相互抵消,从而产生群体的智慧。
说完了如何克服overfitting,即如何应对偏激。但最值得关心的问题是我们应该怎样对待偏激,年轻人难免偏激,一个社会如何能健康的对待偏激,值得深思。在神经网络的实现里,网络出现了overfitting,不是坏事,因为这说明我们的网络足以描绘所有相关的feature,我们的网络足以应对其所需解决问题的复杂度,且我们可以采取种种措施,来克服overfitting。同样年轻人偏激,也不是应当成是洪水猛兽。相反,在设计神经网络时,如果没有出现overfitting的问题,反而说明我们的网络过于简单,hidden unit太少,或者需要加入新的hidden layer,使网络先overfitting,再试图解决overfitting的问题。因此,一个光明的结论摆在我们面前,偏激是通向进步的阶梯,是不可或缺的半成品。如果你年轻时没有偏激过,也就无法走向真正的成熟。我知道我这样写东西就很偏激,可是我看神经网络课程时就是这么想的,因为真实,也就不在乎别人的看法了。我还是坚信,与其做一个快乐的愚人,不如做痛苦的智者,通过构造量化的模型,我们可以客观的去看人类社会出现的问题,为争辩提供一个平台,而不是各自的自说自话。
|
|




 发表于 2015-5-20 10:03:54
发表于 2015-5-20 10:03:54