好久不见大家。今天给大家推荐的是来自大牛 Jürgen Schmidhuber 的工作,《Recurrent Highway Networks》[1]。另外这篇工作也和曾经将 LSTM 的模型的各种 variant 做横向对比的 LSTM Odyssey[2] 是出自同一个团队。这篇论文为一些在 RNN 方面的 trick 做了理论上的统一,并且提出了一种将 RNN 在与 time 的方向相垂直的 space 方向(论文中采用这个词,但并一定准确)上增加 depth 的新模型——即 Recurrent Highway Networks。一些同学可能已经能从名字中看出端倪,这篇论文就是使用了 Highway Networks[3] 的 architecture 来进行纵向扩展。
那么先说说,我们为什么要让 RNN 做一些纵向上的扩展,这所谓的“纵向”又是什么呢?大家都知道 RNN,是在时间轴上做一种 micro time steps 的 tick 循环,从而有一种 time 方向上的 depth,如果这个我们叫做“横向的” depth。那么这篇论文[1] 则是希望进行与这个方向垂直的,一种 space 方向上的扩展。这个 space 是说,在 recurrent state transition 上增加 depth——为“纵向”的 depth——起名为 recurrence depth。这个 depth 怎么增加呢?就是用 Highway Networks 的方式,增加一个 deep net 去计算从 (h_t, x_t) 到 h_{t+1} 的转移。说到这里,是不是这样做的原因已经很明白了?因为众所周知的 RNN 甚至 LSTM 梯度信息传递的困难,大家总是希望能有更 efficient 或者更 effective 的方式,去把 gradient information flow 在两个 state 之间进行传递。这篇论文[1] 的出发点也是如此。
有了出发点,怎样入手呢?由于这篇论文[1] 的作者曾经对 LSTM variant 做过很深入的研究[2],他们甚至找到了一个比较统一的理论框架,去解读 RNN 这种模型在 gradient information flow 问题上的各种边界情况。他们首先定义了 temporal Jacobian 如下:
然后利用一个叫做 Geršgorin circle theorem (GCT) 的定理,得到了 Jacobian 的 spectral radius、recurrent weight matrix R 和 graident vanishing/exploding 的关系。
虽然这个定理比较生僻,但是图示和 intuitive 的理解很容易。大家甚至可以从 Bengio 在 ICML 2016 Back-to-the-future Workshop 上给的 talk 中获得一些启发。如果我们要稳定地去存储 1 bit information,我们需要做的就是 spectral radius 小于1:
而这又可以和我们的 recurrent transition matrix R 做好关联。多个 spectral radis 小于1 的 matrices 连乘就相当于一个 spectral radius 指数型收敛于0 的 matrix:
于是乎,就像这篇论文[1] 的结论一样,gradient vanishing problem 的出现,就是当我们用一些标准差接近0(zero-mean Gaussian)的方式去为 recurrent transition matrix R 做初始化和使用 L1/L2 weight regularization 的 trick 时,一般就会使得 spectral radius 小于1。而当我们用标准差比较大的方式去做这件事,就正好相反啦,就会出现 gradient exploding problem。那么一个边界情况是啥呢,就是我们正好用 identity matrix(或者 scaled identity matrix)做 R 的初始化,就像[4] 论文提出的那样,这时候 specturm 就更容易落在1这个中心附近,gradient 也就不容易出现 vanishing/exploding。所以稍微总结一下,这个 RNN 的 gradient information flow,是和 recurrent transition matrix R 的 Jacobian eigenvalue 有很大关系的,而这个 eigenvalue 的数值很容易被我们的初始化影响。
但是 eigenvalue 的数值,不只是会被初始化影响,还会在 training 的过程中继续改变呀,所以直接把 R 初始化成 identity matrix(IRNN)的方法,并不能完全保证良好的 gradient information flow。这也是为啥一般这种时候,我们会采用比较小的学习率的原因。所以这篇论文[1] 还是想在除了初始化以外的地方,去改进 gradient information flow 的机制。他们另辟蹊径,在计算 recurrent state transition 时使用 highway networks 做 deep net,并把这种改进的 RNN architecture 叫做 Recurrent Highway Networks(RHN)。如下,一个拥有 recurrence depth = L 的 RHN 层:
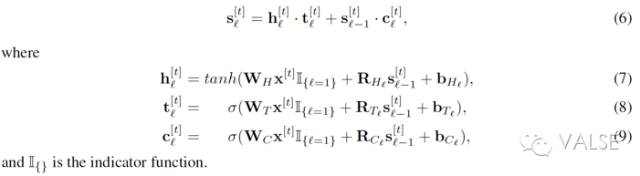
这里的 t_l 和 c_l 就是对应 highway networks[2] 中的 transform gate 和 carry gate。
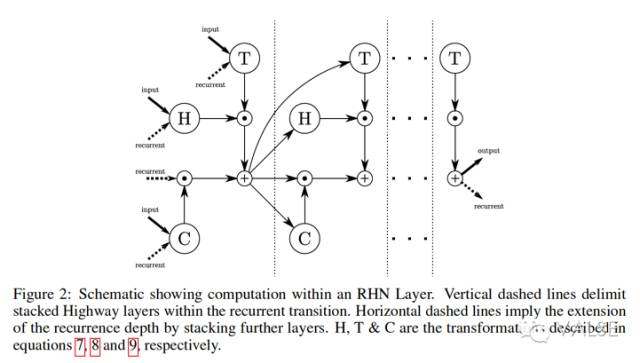
除了上面这种图示,我们还可以把 RHN 与其它常见的 LSTM variant 做对比。个人感觉,当我们的 recurrence depth L=1 时,这个特殊情况的 RHN 与 GRU 非常相似,只不过 GRU 多一个 reset gate。而与 LSTM 相比的话,LSTM 多的是 output gate,以及合并后的 input 和 forget gate,还有一个 output activation function。所以说到这里,RHN 的“优势”和特点就很明显了。首先是,与 highway networks 结合的它,使得它可以将信息无转化的在 hidden state 间传递(carry gate)。第二,它不像 GRU 和 LSTM 一样,需要通过 activation function,而这会带来很大的不同。说完这些 variant 的对比,就不得不说到这篇论文[1] 的不足之处。它和 GRU 以及一些相关 LSTM variant 的区别讨论不足,实验对比也不足。比如在实验部分根本没有加入 GRU。作者在网上承诺将在下一个版本内补上。
接下来就是把刚才利用 GCT 定理的分析和作者提出的 RHN 架构结合在一起的时候啦。作者发现,利用 GCT 定理,RHN 的优点有以下几个:(1)首先就跟 highway networks 一样,RHN 的 transform 和 carry gates 让它变得更灵活一点;(2)这个灵活性是作者认为他们的 RHN 比别人的表现更好的原因。也就是说,当应对复杂的 complex sequences modeling 的时候,它更灵活,又好 training,那不就相当于它的 representation ability 和 optimization ability 都更强么?
最后就是实验啦,实验是它的弱项。对比不够充分,而且在使用的优化方法上也不够有说服力。对比不充分是它没有和非常相似的 GRU 或者 IRNN 做对比。以及它既然对比了 Grid-LSTM,却没有更深入的分析 RHN 和 Grid-LSTM 的区别(甚至没有 cite),实验的结果都是直接 copy 自 Grid-LSTM 的论文。第二是,它的优化方法采用的是 Momentum SGD,而不是 Adam 这些 learning rate 可以调整的优化方法。那么显然,这个对于 RHN 的 optimization ability 比别人更好,是不太有说服力的。
综上,推荐这篇论文的原因主要是它从另一个简单的方式将 RNN 在 recurrence depth 上进行了改造,使得 RNN 的建模更加灵活和强大。但它提出的 RHN 到底多强大,也就是这种改造方法,比起 Grid-LSTM 等相似方法,到底能好出多少,还需要更多的分析和实验。
[1] Julian Georg Zilly, Rupesh Kumar Srivastava, Jan Koutník, Jürgen Schmidhuber. "Recurrent Highway Networks". 2016 arXiv preprint.
[2] Klaus Greff, Rupesh Kumar Srivastava, Jan Koutník, Bas R. Steunebrink, Jürgen Schmidhuber. "LSTM: A Search Space Odyssey". 2015 arXiv preprint.
[3] Rupesh Kumar Srivastava, Klaus Greff, and Jürgen Schmidhuber. "Highway networks". arXiv preprint arXiv:1505.00387, 2015.
[4] Q. V. Le, N. Jaitly, and G. E. Hinton. A Simple Way to Initialize Recurrent Networks of Rectified Linear Units. ArXiv e-prints, April 2015.




 发表于 2016-7-22 14:48:02
发表于 2016-7-22 14:48:02