http://mp.weixin.qq.com/s?__biz=MzA3Mjk0OTgyMg==&mid=402584442&idx=1&sn=32fc7f4ba41d5024922e6122f0bdf013#rd
【VALSE前沿技术选介16-10期】今天介绍另一篇图像生成的文章[1],其提出的 DeePSiM 已经开始被 Fei-Fei Li 等 Vision 大组用了起来。这篇文章,可以看做两位作者对于之前自己的另一份很有影响力的工作《Inverting Convolutional Networks with Convolutional Networks》[2]的延续。
在上一篇 Invert 的工作[2]中,两位作者主要想探讨的是通过 CNN 学出来的 image feature 是否可以用来 re-generate (invert) 原始的 natural images。通过大量的实验和分析,两位作者得到了一些很重要的观察和结论。其中一个观察是,他们发现尽管这些 feature 确实可以在一定程度上 invert 出 image 来,并且在 high-level layer 的 feature 里仍然能保留一些 color 等重要信息——可是 re-generated 出来的 image 都比较 blurry。这里可以分析出两个事情,一个事情是,尽管 feature space-image space 之间的映射不是一对一的,也就是说不同的 image(无论 natural 与否)都可能得到同样的 feature mapping,但是却仍然可以 invert 出看起来不错的 natural image——也就是说 invert reconstruction 是有局限性的,只会倾向于生成 natural image(这个结论在 DeePSiM 中没有出现,而是在 invert 论文[2]中提到了)。另一个事情是,得出的 image 虽然 natural 但很 blurry,那么具体的 values of features 是没什么用的,而且说明即使是在 feature space 的 reconstruction loss 可能也不适合做 image generation——常用的 squared Euclidean 会 average detail 信息,得到模糊的图片。
所以,只是从 image space 的 per-pixel loss 走到 feature space loss 也是不够的。于是就有了这篇 DeePSiM 的工作[1]。所谓的 DeePSiM 是“a class of losses”,其实就是几个 loss 的 weighted sum,具体可以见公式(1)。用 feature loss 替代 element-wise loss(per-pixel) 的思想和把多个 loss 结合在一起的思想并不新鲜——在之前已有人提出了将 AutoEncoder 和 GAN 结合在一起的工作[3]。但是,这篇工作的贡献(和区别)在于,他们将这种多个 loss 结合的方式提炼到了更 general 的框架层面,从而 comparator 不再必须是 discriminator 的一部分——使得这种 loss 不再局限于 VAE 模型和单向 image generation 应用。 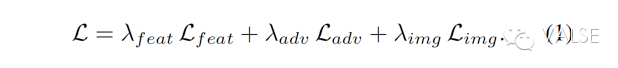
具体来看公式(1)中的几种 loss。最重要的就是 feature loss,L_feat。这个 loss 实现了将 image space 转到 feature space,可是就像之前分析的单有 feature loss 是不行的——只会得到很多 artifacts。为此,他们继续加入了 GAN 的 adversarial loss 来为生成的 image 提供一种 trained prior。最后,也是他们的一个小创新,就是第三种 loss。他们并没有完全抛弃 image space information,而是将 class information 作为 image loss,L_img 加入到了 DeePSiM 中来。这一点上很像 conditional GAN,而且过去的实验表明,class of image 这个信息对于 generation 从 nonsense 变到 sensible 是很重要的[4]。所以最后,这三种 loss 对应的三个框架 component 就是,一个 generator 用于实现 generation function,L_feat 对应于 comparator 计算 feature space 的 information,L_adv 对应 GAN 中的 discriminator 用于 training objective,而 L_img 作为辅助去 stable 整个 training 过程。 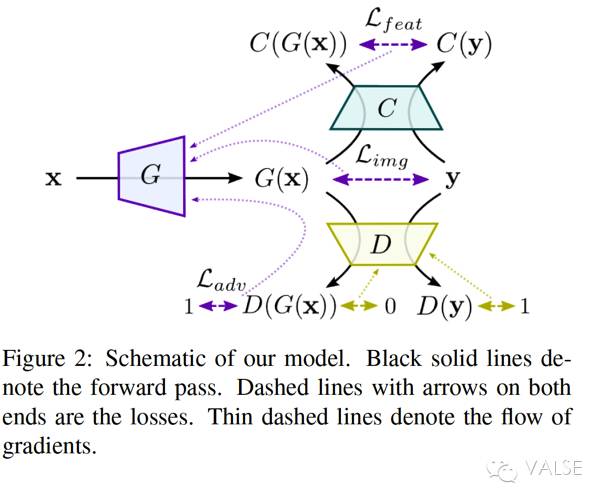
那么,在实验部分他们也是做的比较 extensive。实验的重点肯定是验证新的 loss DeePSiM 更有效: 
为此,他们用了很多种 CNN 结构,并设计了三种 application:image autoencoder,image generation with (modified) VAE,invert image generation(iterative re-encoding)。比较有趣的是 interative re-encoding,就是反复进行 image->encode->feature->invert image generation->encode->feature...这样的过程。只不过,实验中个人不太理解和希望改进的点是:(1)image generation with modified VAE 中,VAE 改造的方法不是很 straightforward,他们将 VAE 中的目标逼近 latent vector z,变成了两个更细致的 \mu 和 \sigma,这样改造出的 KL divergence 是否会过于 favor to CNN;(2)image inversion 的过程主要是为了看学到的 feature 到底多大程度的保留了 image properties。在作者之前的工作[2]中,就有 imply 其实 top-5 的 activations 可能就能非常好的做好 reconstruction——希望能做这样的实验,像 knowledge distillation 一样。 最后总结一下,这篇论文中提出的 Perceptual Loss 并不能说是一个非常新的想法,但是这篇文章整体上的各种分析还是比较有深度,作为了解这边工作的一个突破口是很好的。另一方面,Fei-Fei Li 组最近也有一篇将 Perceptual Loss generalized 到 image transformation 这个 general task 上的工作[5]。大家有兴趣也可以看看。
[1] Alexey Dosovitskiy, Thomas Brox. Generating Images with Perceptual Similarity Metrics based on Deep Networks. 2016. arXiv preprint: 1602.02644. [2] Alexey Dosovitskiy, Thomas Brox. Inverting Convolutional Networks with Convolutional Networks. CVPR 2016. [3] Anders Boesen Lindbo Larsen et al. Autoencoding beyond pixels using a learned similarity metric. 2015. arXiv preprint: 1512.09300. [4] Emily Denton et al. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. 2015. arXiv preprint: 1506.05751. [5] Justin Johnson, Alexandre Alahi, Li Fei-Fei. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. 2016. arXiv preprint: 1603.08155.
| 



 发表于 2016-4-7 16:27:31
发表于 2016-4-7 16:27:31