http://mp.weixin.qq.com/s?__biz= ... yWutXHWL6TEmHT5i#rd
【VALSE前沿技术选介16-02期】2016-02-23 Winsty [url=]VALSE[/url]
这次给大家带来的还是来自Google Deepmind的paper “Pixel Recurrent Neural Networks”,于1月25日上传在Arxiv。 本文想做的事情是建立一个像素级别的图片生成模型,即对一张图片中所有像素的联合概率进行建模,如果图片大小是 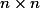 ,则我们需要建模的是 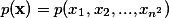 。然而直接计算这个概率在较大的时候复杂度过高,并不适合。一种解决方案便是NADE [1],NADE将联合概率转换为一系列条件概率的乘积,即
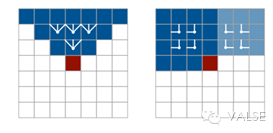
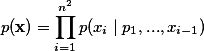 一个直观的解释便是当生成第个元素的时候,依赖于之前所有个元素,这也是NADE中autoregressive的含义。这样我们便可以把建模联合概率的问题转化为更容易的建模条件概率的问题。本文的核心贡献就在于用LSTM对此条件概率进行建模,从而可以捕捉到长期的依赖关系,从而改善图片生成模型的结果,让模型有更好的“全局观”。文章中提出了两种建模的方式: 1) Row LSTM:即按行生成像素,每一个像素和上一行中这个像素有关,这个像素与联合决定了在此时刻LSTM gate和memory的状态。然而这个方法存在一个问题,即每个像素并不能完整看到之前所有的像素的信息,而只是一个三角区域。具体公式见原文公式(3) 2) Diagonal BiLSTM:此模型从图像的左上角和右上角分别开始,到达另一侧的底部。一左上角开始的LSTM为例,每个像素与和相关,这样的好处是结合两个LSTM,每个像素可以看到其上侧和左侧的所有像素,从而可以学习到更好的依赖关系。
这两种方法的比较在下图中,实验中也验证了后者的效果会比前者略好。
此外,文中还讨论了很多实现细节和技巧,例如如何处理RGB三通道图片,如何使用Residual Connection训练更深层的网络以及如何使用Multi-scale使得生成的大图效果更好等等,这些细节这里就略过。
实验部分,定量的部分也略过,只是和之前的一些模型比较Negative Log Likelihood。比较有意思的是定性的结果,即真正生成的图片和补全的图片。粗略看来,完全随机生成的结果并无不自然之处,而在图像补全的应用中,Pixel RNN甚至可以记录下物体部分的轮廓,将一个半圆补全。这都验证了Pixel RNN的长时间记忆能力。

 简单点评:直接做像素级别的生成模型为很多low level vision的任务打开了一扇新的大门,然而Pixel RNN生成的图片乍看上去和自然图片并没差,然而仔细观察后会发现,其实这些图片在语义上欠缺很大,大多是无意义的图片。下面如何将更多的语义信息结合到生成模型中将会是一个有意思的研究方向。 [1] Larochelle, Hugo, and Iain Murray. “The Neural AutoregressiveDistribution Estimator.” AISTATS. Vol. 6. No. 20. 2011.
| 



 发表于 2016-2-25 23:54:01
发表于 2016-2-25 23:54:01